このラボでは、Amazon EMR クラスターの Hue (Hadoop User Experience) を使用して Pig スクリプトを実行し、ログファイルを処理して出力を Amazon S3 に保存します。
まず、SSH トンネルを使用して Hue インストールに接続するようにローカルクライアントを設定します。次いで、Hue クライアントに新しいユーザーを作成します。Hue に接続したら、Hue の Pig エディタに Pig スクリプトをコピーし、スクリプトを実行します。次に、Pig ジョブが完了したら、ラボ環境の Amazon S3 バケットに保存されたジョブの出力を確認します。最後に、Amazon CloudWatch と Ganglia を使用してクラスターをモニタリングします。
このラボでは、Amazon EMR で実行するために、Hue 経由でコマンドを実行する 1 つの方法として Pig を使用します。ただし、このラボの目的は Pig 言語の使用方法を学習することではありません。お客様が他のスクリプト言語またはデータ操作言語にご興味やご経験がある場合には、このスクリプトを簡単に実行できるかもしれません。しかし、このラボの目的は、スクリプトを単純にコピーして貼り付け、それを実行することです。
目標
このラボを完了すると、以下の操作を実行できるようになります。
所要時間
このラボは、修了までに約45 分かかります。
注意
Qwiklabs画面の右にある [ラボを開始] をクリックして、ラボを起動します。
Qwiklabs画面の左側に表示されている[コンソールを開く] をクリックします。
Qwiklabs画面の左側に表示されている認証情報を使用して AWS マネジメントコンソールにサインインします。
このラボの間は、リージョンを変更しないでください。
ラボのこのセクションでは、Amazon EMR クラスターで Hue および Ganglia に接続できるように、SSH トンネルを設定します。
[1] AWS マネジメントコンソールの [サービス] で [EMR] をクリックします。
[2][クラスター一覧] ページで、[labcluster] をクリックします。(複数ある場合は、最初のものをクリックします)。
[3][マスターパブリック DNS 名] をクリップボードにコピーします。後で使用できるように、テキストエディタに貼り付けます。
Windows の PuTTY クライアントで SSH トンネルを設定します。Hue、Hadoop、Ganglia、およびその他のアプリケーションは、マスターノードでホストされるウェブサイトとしてユーザーインターフェイスを公開しています。セキュリティ上の理由から、これらのウェブサイトは、マスターノードのローカルウェブサーバー (http://localhost:port) でのみアクセスできます。インターネットでは公開されていません。マスターノードでローカルウェブサーバーに接続するために、ご使用のコンピュータとマスターノード間に SSH トンネルを作成できます (これは [ポートフォワーディング] とも呼ばれます)。
この手順は Windows ユーザーのみを対象としています。
Mac または Linux を使用している場合は、このセクションを省略して次のセクションに進んでください。
[4] ラボの開始ボンタンを押した画面の左側にある、[ PPK形式でダウンロード] をクリックします。
[5] ディレクトリを指定してファイルを保存します。
PuTTY を使用して Amazon EC2 インスタンスに SSH で接続します。
コンピュータに PuTTY がインストールされていない場合は、ここからダウンロードしてください。
[6] PuTTY.exe を開きます。
[7] PuTTY セッションの設定を行います。
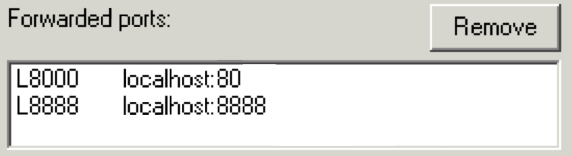
8000localhost:808888localhost:8888設定は次のようになります。
[10][Open] をクリックして、セッションを開始します。
[11] サーバーのホストキーをキャッシュするように求められたら、[Yes] をクリックします。
[12] ユーザー名の入力を求められたら、hadoopと入力します。
これは、EC2 インスタンスで使用される通常の [ec 2-user] ログインとは異なります。
これにより、EC2 インスタンスに接続されます。
Windows ユーザーはこちらをクリックして次のタスクに進んでください。
この手順は Mac または Linux ユーザーのみを対象としています。Windows を使用している場合は、次のタスクに進んでください。
[13] ラボの開始ボンタンを押した画面の左側にある、[ PEM形式でダウンロード] をクリックします。
[14] ディレクトリを指定してファイルを保存します。
[15] 以下のコマンドをテキストエディターにコピーし、SSH トンネリングをポート 8000 とポート 8888 に使用します。
chmod 400 KEYPAIR.pem
ssh -i KEYPAIR.pem -L 8000:localhost:80 -L 8888:localhost:8888 hadoop@MASTER-PUBLIC-DNS
以下に例を示します。
chmod 400 Downloads/qwikLABS-L123-1234.pem
ssh -i Downloads/qwikLABS-L123-1234.pem -L 8000:localhost:80 -L 8888:localhost:8888 hadoop@ec2-54-111-222-333.us-west-2.compute.amazonaws.com
[17] 編集したコマンドをターミナルウィンドウに貼り付けて実行します。
[18] リモート SSH サーバーへの最初の接続を許可するかを確認するメッセージが表示されたら、yesと入力します。
Hue にアクセスするには、ローカルポート 8888 に接続します。この接続は SSH 接続を経由して、Hue が実行されている EMR クラスターのマスターノードのポート 8888 に転送されます。
http://localhost:8888
[https://] ではなく、[http://] を使用していることを確認してください。
HadoopHue1234!Hue では、[Hadoop] ユーザープロファイルには HDFS への完全なアクセス権限が含まれているのに対し、標準の管理者アカウントには含まれていません。
[22] ページの左上の [ホームボタン] をクリックします。
[23][Did you know?] ウィンドウが表示された場合は、[Got it, prof!] をクリックします。
ラボのこのセクションでは、外部の Amazon S3 バケットからお客様の Amazon S3 バケットに Pig スクリプトをコピーし、このスクリプトから Hue の Pig エディタにテキストをコピーします。次に、このスクリプトを Pig ジョブとして実行し、お客様の Amazon S3 バケットに保存されたそのジョブの結果を表示します。
まず、Pig で使用する Amazon S3 バケットを作成し、Hue を使用してバケット内部に 2 つのディレクトリを作成します。
Amazon S3 の各バケットには一意の名前が必要になります。そこで、ランダムな数値をバケット名に追加します。
[24] AWS マネジメントコンソール の [サービス] で [S3] をクリックします。
[25] [Create Bucket] をクリックします。
[26][バケット名] には、次のように入力します。pig-bucket-123 (123 の部分は乱数で置き換え)
バケット名を覚えておきます。後ほどラボで使用します。
[27][作成] をクリックします。
[28] Hue ブラウザのタブで、ページの上部の [File Browser] テキストボタンをクリックします。
画面でブラウザウィンドウが十分に幅広くなかったり、ブラウザで分割画面表示を行っていたりする場合には、リンクのテキストの代わりにアイコンが表示されます。
Hue ファイルブラウザに Pig バケットが表示されます。
[30][pig-bucket-xxx] バケットをクリックします。
[31] 右上隅の [New] をクリックした後に [ディレクトリ] をクリックします。
ブラウザウィンドウが十分に幅広くない場合は、右側にスクロールするか、またはブラウザウィンドウの幅を広げて、[New] アイコンが表示されるようにします。
outputと入力し、[Create] をクリックします。Amazon EMR で Hue を使用することには、Amazon S3 の統合が組み込まれているという利点があります。そのため、Hue の適切なアクセス権限を持っているユーザーは、Hue で Amazon S3 ファイルシステムの機能のほとんどをネイティブに使用できます。また、ユーザーは他のアカウントからバケットを Hue ファイルシステムに追加できます。
scriptsという名前の別のディレクトリを作成します。ここでは、Amazon S3 バケット内に Pig スクリプトを作成します。
[34] ページの上部で、[Query Editors] をクリックしてから [Pig] をクリックします。
[35] 以下のスクリプトをコピーしてエディタに貼り付けます。
--
-- setup piggyback functions
--
DEFINE EXTRACT org.apache.pig.piggybank.evaluation.string.EXTRACT;
DEFINE FORMAT org.apache.pig.piggybank.evaluation.string.FORMAT;
DEFINE REPLACE org.apache.pig.piggybank.evaluation.string.REPLACE;
DEFINE DATE_TIME org.apache.pig.piggybank.evaluation.datetime.DATE_TIME;
DEFINE FORMAT_DT org.apache.pig.piggybank.evaluation.datetime.FORMAT_DT;
--
-- import logs and break into tuples
--
raw_logs =
-- load the weblogs into a sequence of one element tuples
LOAD '$INPUT' USING TextLoader AS (line:chararray);
logs_base =
-- for each weblog string convert the weblong string into a
-- structure with named fields
FOREACH
raw_logs
GENERATE
FLATTEN (
EXTRACT(
line,
'^(\\S+) (\\S+) (\\S+) \\[([\\w:/]+\\s[+\\-]\\d{4})\\] "(.+?)" (\\S+) (\\S+) "([^"]*)" "([^"]*)"'
)
)
AS (
remoteAddr: chararray, remoteLogname: chararray, user: chararray, time: chararray,
request: chararray, status: int, bytes_string: chararray, referrer: chararray,
browser: chararray
)
;
logs =
-- convert from string values to typed values such as date_time and integers
FOREACH
logs_base
GENERATE
*,
DATE_TIME(time, 'dd/MMM/yyyy:HH:mm:ss Z', 'UTC') as dtime,
(int)REPLACE(bytes_string, '-', '0') as bytes
;
--
-- determine total number of requests and bytes served by UTC hour of day
-- aggregating as a typical day across the total time of the logs
--
by_hour_count =
-- group logs by their hour of day, counting the number of logs in that hour
-- and the sum of the bytes of rows for that hour
FOREACH
(GROUP logs BY FORMAT_DT('HH',dtime))
GENERATE
$0,
COUNT($1) AS num_requests,
SUM($1.bytes) AS num_bytes
;
STORE by_hour_count INTO '$OUTPUT/total_requests_bytes_per_hour';
--
-- top 50 X.X.X.* blocks
--
by_ip_count =
-- group weblog entries by the ip address from the remote address field
-- and count the number of entries for each address as well as
-- the sum of the bytes
FOREACH
(GROUP logs BY FORMAT('%s.*', EXTRACT(remoteAddr, '(\\d+\\.\\d+\\.\\d+)')))
GENERATE
$0,
COUNT($1) AS num_requests,
SUM($1.bytes) AS num_bytes
;
by_ip_count_sorted =
ORDER by_ip_count BY num_requests DESC;
by_ip_count_limited =
-- order ip by the number of requests they make
LIMIT by_ip_count_sorted 50;
STORE by_ip_count_limited into '$OUTPUT/top_50_ips';
--
-- top 50 external referrers
--
by_referrer_count =
-- group by the referrer URL and count the number of requests
FOREACH
(GROUP logs BY EXTRACT(referrer, '(http:\\/\\/[a-z0-9\\.-]+)'))
GENERATE
FLATTEN($0),
COUNT($1) AS num_requests
;
by_referrer_count_filtered =
-- exclude matches for example.org
FILTER by_referrer_count BY NOT $0 matches '.*example\\.org';
by_referrer_count_sorted =
-- take the top 50 results
ORDER by_referrer_count_filtered BY $1 DESC;
by_referrer_count_limited =
-- take the top 50 results
LIMIT by_referrer_count_sorted 50;
STORE by_referrer_count_limited INTO '$OUTPUT/top_50_external_referrers';
--
-- top search terms coming from bing or google
--
google_and_bing_urls =
-- find referrer fields that match either bing or google
FILTER
(FOREACH logs GENERATE referrer)
BY
referrer matches '.*bing.*'
OR
referrer matches '.*google.*'
;
search_terms =
-- extract from each referrer url the search phrases
FOREACH
google_and_bing_urls
GENERATE
FLATTEN(EXTRACT(referrer, '.*[&\\?]q=([^&]+).*')) as (term:chararray)
;
search_terms_filtered =
-- reject urls that contained no search terms
FILTER search_terms BY NOT $0 IS NULL;
search_terms_count =
-- for each search phrase count the number of weblogs entries that contained it
FOREACH
(GROUP search_terms_filtered BY $0)
GENERATE
$0,
COUNT($1) AS num
;
search_terms_count_sorted =
-- take the top 50 results
ORDER search_terms_count BY num DESC;
search_terms_count_limited =
-- take the top 50 results
LIMIT search_terms_count_sorted 50;
STORE search_terms_count_limited INTO '$OUTPUT/top_50_search_terms_from_bing_google';
[36] ナビゲーションペインで [保存] をクリックします。
[37] Pig log transformという名前でファイルを保存します。
[38] ナビゲーションペインの [Submit] をクリックして、Pig スクリプトを実行します。
[39] 以下の値を入力します。
s3://aws-tc-largeobjects/AWS-200-BIG/v3.1/lab-5-pig-hue/data/s3://pig-bucket-xxx/output/
スクリプトの実行には数分かかります。
ページに表示される進捗バーを使用してジョブの進行状況を追跡します。バーが緑色に変わって [Progress: 100%] と表示されたら、バッチジョブは完了し、ブラウザにログが自動的に表示されます。
待っている間、 [Pig] をクリックしてスクリプトの内容を閲覧して、ジョブが何をしているか理解することもできます。次に、 [Logs] をクリックして、スクリプトの進行状況を確認します。
ジョブが完了する前に Hue 内で移動しないでください。移動すると、ジョブのステータスページに戻れなくなる可能性があります。ステータスページからどうしても移動する必要がある場合には、[Pig Editor] ページに移動して [Dashboard] をクリックし、[Running] または [Completed] の見出しの下の [Pig log transform] ジョブをクリックして、ステータスページに戻ります。
これで、ジョブの出力を表示できるようになりました。
[41] [File Browser] をクリックします。
[42] [S3] をクリックして、Amazon S3 ルートディレクトリに戻ります。
[43][pig-bucket-xxx] バケットをクリックします。
[44][output] ディレクトリをクリックします。
[output] 内にサブディレクトリのコレクションが表示されます。
[45][top_50_external_referrers] サブディレクトリをクリックします。
[46][part-r-00000] ファイルをダブルクリックします。
このファイルには、Pig スクリプトの一部の結果が表示されます。この結果には外部参照者エントリがカウントされています。このファイルには、上位 50 の外部参照者と、このウェブサイトによって見込み客に広告が行われた回数が保存されています。
時間がある場合は、その他のサブディレクトリも閲覧して、完了した Pig ジョブの結果を確認します。各サブディレクトリは、実行したバッチジョブ全体における個別のジョブを表します。
これらの各サブディレクトリには「_SUCCESS」というファイルもあります。これは標準の Apache Hadoop 規則で、このディレクトリを作成したマップまたはリデュースフェーズが正常に実行されたことを単に示す空ファイルです。
これらの各エントリは、Pig によって実行されたさまざまな MapReduce ジョブの一部です。ここから、ジョブの各部分の stdout、stderr、syslog のレポートと、関連するその他多くのメタデータを実際に確認できます。
このタスクでは、Amazon CloudWatch を使用してクラスターの基本モニタリング情報を確認します。
クラスターを実行するときには、通常、クラスターの進行状況と状態を追跡する必要があります。Amazon EMR では、クラスターのモニタリングに役立つメトリクスが記録されます。これらのメトリクスは、Amazon EMR コンソールと CloudWatch コンソールで利用できます。CloudWatch では、メトリクスが指定したパラメータ値の範囲外になった場合にアラームが発信されるよう設定できます。
これらのメトリクスは自動的に収集され、各 Amazon EMR クラスターの CloudWatch にプッシュされます。CloudWatch でレポートされる Amazon EMR メトリクスには料金は発生しません。これらは Amazon EMR サービスの一環として利用できます。
メトリクスは 5 分ごとに更新されます。この間隔は設定できません。メトリクスは 2 週間アーカイブされます。その期間が過ぎると、データは破棄されます。
お客様にとって興味深いと思われる、次のようなメトリクスがあります。
クラスターの進行状況を追跡するには、[RunningMapTasks]、[RemainingMapTasks]、[RunningReduceTasks]、[RemainingReduceTasks] メトリクスを調べます。
アイドル状態のクラスターを検出するには、[IsIdle] メトリクスを調べます。[IsIdle] は、クラスターがタスクを現在実行していないライブのタスクかどうかを追跡します。30 分など、一定期間の間クラスターがアイドル状態の場合、アラームが発生するように設定できます。
ノードのストレージがいつ使い果たされるかを検出するために、[HDFSUtilization] メトリクスを調べます。[HDFSUtilization] は、現在使用されているディスク容量の割合です。これが使用されるキャパシティーの 80% など、アプリケーションの許容レベルを超えた場合は、クラスターのサイズ変更およびコアノードの追加が必要な場合があります。
Amazon EMR によって記録されるメトリクスの詳細なリストについては、次のドキュメントを参照してください。Metrics Reported by Amazon EMR in CloudWatch
Amazon EMR によって Amazon CloudWatch にプッシュされるメトリクスを利用する方法はさまざまです。それらを、Amazon EMR コンソールまたは CloudWatch コンソールで表示することも、CloudWatch CLI または CloudWatch API を使用して取得することもできます。
ラボのこのセクションでは、CloudWatch でクラスターの統計情報を表示します。
[48] AWS マネジメント コンソール に戻ります。
[49][サービス] から [EMR] をクリックします。
[50][labcluster] をクリックした後に [モニタリング] タブをクリックします。
モニタリングセクションでは、 [Cluster Status]、[Node Status]、[IO] メトリクスなどを表示できます。グラフをクリックして拡大できます。
[HDFS Utilization] (HDFS 使用率) と [Memory Available MB] (メモリの使用可能 MB) のメトリクスを確認します。これらのメトリクスはクラスターノードのメモリの使用率をチューニングするのに役立ちます。
時間がある場合は、CloudWatch で利用できるその他のメトリクスも調べてください。
Ganglia オープンソースプロジェクトは、スケーラブルな分散型システムであり、クラスターおよびグリッドのパフォーマンスへの影響を最小限に抑えながら、それらをモニタリングできるように設計されています。クラスターで Ganglia を有効にすると、レポートを生成し、クラスター全体のパフォーマンスを表示でき、個別のノードインスタンスのパフォーマンスを検査できます。Ganglia オープンソースプロジェクトの詳細については、http://ganglia.info/ を参照してください。
このタスクでは、Ganglia を使用して、クラスターの統計情報と基本モニタリング情報を表示します。Ganglia には localhost:8000 でアクセスできます。この接続は SSH 接続を経由して、マスター EMR ノードのポート 80 に自動的に転送されます。
http://localhost:8000/ganglia
Ganglia インターフェイスがロードされたら、左側の一般的な統計を確認します。

また、メトリクスが CloudWatch によってレポートされたメトリクスとどのように異なるかについても確認します。特に、クラスターの CPU 使用率を確認します。
下にスクロールすると、クラスターのロードとクラスターのメモリメトリクスを確認できます。
[54] ページの下方にスクロールし、[Metric] プルダウンメニューをクリックします。
[55] jvm.JvmMetrics.MemHeapUsedMとタイプし、そのメトリクスを選択します。
ウィンドウの下部にスクロールし、各ノードに表示されているグラフを確認します。特に、マスターノードのメモリ使用率を確認します (Ganglia には、ノードを識別するプライベート IP アドレスが表示されます)。
マスターノードで使用されているメモリヒープとコアノードで使用されているメモリヒープを比較します。

[56] マスターノードのメモリヒープ使用率を示すグラフをクリックします。これにより、ノードのメトリクスを示すノードビューが表示されます。
[57] 下にスクロールし、ノードの各メトリクスグラフを確認します。
[58] 時間がある場合は、ツールバーからレポート対象として選択できる多数のメトリクスを調べます。クラスターの各ノードのメトリクスは自由に調べてください。
お疲れ様でした。 このラボを完了しました。以下の手順に従って、ラボ環境をクリーンアップします。
[59] AWS マネジメントコンソールからサインアウトするには、コンソール上部のメニューバーで [awsstudent] をクリックし、[サインアウト] をクリックします。
[60] Qwiklabs ページで [ラボを終了] をクリックします。