このラボでは、Amazon Kinesis を使用して、Apache サーバーログの分析とストリーミングの処理を行います。Amazon Kinesis Analytics アプリケーションを起動し、Amazon Kinesis ログストリームに接続します。Amazon Kinesis ログストリームによって、アプリケーションサーバーからのログがリアルタイムでストリーミングされています。Amazon Kinesis ストリームをモニタリングし、SQL を使用して 2 つの出力ストリームを作成します。1 つめのストリームでは、タンブリングウィンドウで、30 秒ごとに HTTP リクエストがモニタリングされます。2 つめのストリームでは、すべての着信 404 HTTP リクエストが、スライディングウィンドウを使用してモニタリングされます。404 ストリームログを Amazon Kinesis Firehose に接続し、Amazon S3 にログを保存します。
目標
このラボを完了すると、以下の操作を実行できるようになります。
前提条件 このラボの前提条件は以下のとおりです。
所要時間 このラボの所要時間は約 45 分です。
注意
シナリオ この演習では、サンプルアプリケーションサーバーからの着信 Apache サーバーログの、ウェブサイトのヒットと 404 エラーをモニタリングし、処理します。その後、新バージョンがリリースされます。アプリケーションサーバーは、Amazon API Gateway を使用して Amazon Kinesis Stream にサーバーログをロードするように設定されています。一般的な Common Log Format の Apache サーバーログのエントリには、単一のリクエストに関する以下の情報が含まれています。
111.22.33.444 - - [19/Nov/1998:05:44:17 -0700] "GET /images/imagename.png HTTP/1.1" 200 124
このラボでは、Amazon Kinesis Analytics アプリケーションを使用して、ストリーミングログエントリのクレンジングと変換を行い、変換後のログを Amazon S3 に保存します。ストリームのモニタリング中に、リクエスト内の大量の 404 (Not Fround) ステータスコードの原因を突き止める作業を行います。
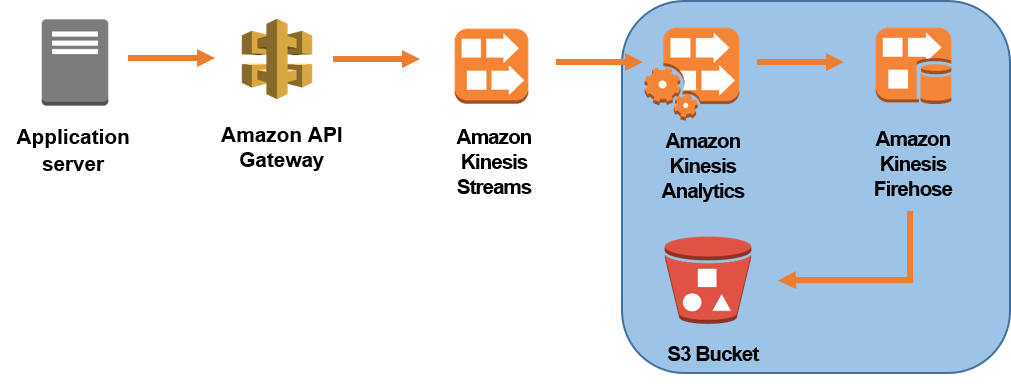
以下のダイアグラムに、アプリケーションサーバーから Amazon S3 へのデータフローを示します。ダイアグラムのハイライトされた部分を、このラボで扱います。このラボからの出力データストリームは、ダッシュボードに入力して、エラー報告をリアルタイムで行うために使用することもできます。
Qwiklabs画面から [ラボを開始] をクリックして、ラボを起動します。
Qwiklabs画面の左側に表示されている[コンソールを開く] をクリックします。
Qwiklabs画面の左側に表示されている認証情報を使用して AWS マネジメントコンソールにサインインします。
このラボの間は、リージョンを変更しないでください。
このタスクでは、Amazon Kinesis Analytics アプリケーションを起動し実行します。Amazon Kinesis Streams や Amazon API Gateway のようなリソースが、ラボアカウント内に既にセットアップされています。
このタスクでは、Amazon Kinesis Analytics アプリケーションを起動して、ソースとなる Amazon Kinesis ストリームをアプリケーションに接続します。
[1] AWS マネジメントコンソールの [サービス] で [Kinesis] をクリックします。
[2][分析アプリケーションの作成] を選択します。
[3][アプリケーション名] には、lab-log-analyticsと入力します。
[4][説明] には、Amazon Kinesis Analytics application for log analyticsと入力します。
[5][アプリケーションを作成] をクリックします。
データーソースに接続することにより、アプリケーションを設定することができるようになりました。
[6][ストリーミングデータを接続] をクリックします。
[7][Kinesis データストリーム] には、InputLogStream を選択します。
これは、ラボ環境の一部として自動的にプロビジョニングされた入力データストリームです。このページでは、SQL クエリは、このソースをSOURCE_SQL_STREAM_001として参照できます。
[8][アクセス許可] には、[Kinesis Analytics が設定できる IAM ロールから選択] をクリックします。
[9][IAM ロール] には、[Kinesis_Analytics_Role] を選択します。
これにより、Kinesis に接続するために必要なアクセス許可をアプリケーションに付与します。
Amazon Kinesis Analytics アプリケーションでは、DiscoverInputSchema API (discovery API) が使用されているため、スキーマが推測され、その結果が UTF-8 でエンコード済みの CSV や JSON といった一般的な形式でコンソールに表示されます。この API によって、ストリーミングソースのレコードのランダムなサンプルを使用して、スキーマ (つまり、列名、データ型、データ要素の入力データ内での位置) が推測されます。コンソールを使用して、列名やデータ型の変更など、スキーマを更新することもできます。
タスク 1.2: リアルタイム分析に Kinesis Analytics を使用する このタスクでは、Amazon Kinesis Analytics を使用してリアルタイム分析を行います。SQL を使用して 404 HTTP ステータスコードの分析と処理を行い、大量の 404 HTTP レスポンスの背後にある理由を見つけます。
[12][Go to SQL editor] をクリックします。
[13][Would you like to start running "lab-log-analytics"] というポップアップウィンドウが表示された場合、[Yes, start application] をクリックします。
アプリケーションが開始されるまで、数分かかります。
[14][SQL editor] セクションで 、SQL エディタ内の既存のコードをすべて削除します。
[15] 次のコードを SQL エディタに貼り付けます。
-- Create intermediate Stream for incoming data
CREATE STREAM "INTERMEDIATE_STREAM" (
hostname VARCHAR(1024),
logname VARCHAR(1024),
username VARCHAR(1024),
requesttime VARCHAR(1024),
request VARCHAR(1024),
status VARCHAR(32),
responsesize VARCHAR(32)
);
-- Data Pump: Take incoming data from SOURCE_SQL_STREAM_001 and insert into INTERMEDIATE_STREAM
CREATE OR REPLACE PUMP "INTERMEDIATE_STREAM_PUMP" AS
INSERT INTO "INTERMEDIATE_STREAM"
SELECT STREAM
l.r.COLUMN1,
l.r.COLUMN2,
l.r.COLUMN3,
l.r.COLUMN4,
l.r.COLUMN5,
l.r.COLUMN6,
l.r.COLUMN7
FROM (SELECT STREAM W3C_LOG_PARSE("browseraction", 'COMMON')
FROM "SOURCE_SQL_STREAM_001"
) AS l(r);
-- Define output stream that stores request counts by status
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (
status VARCHAR(32),
requestCount INTEGER);
-- Data Pump: Take INTERMEDIATE_STREAM and group into 1-minute intervals
CREATE OR REPLACE PUMP "OUTPUT_PUMP" AS
INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM status, COUNT(*) AS requestCount
FROM "INTERMEDIATE_STREAM"
GROUP BY status, FLOOR(("INTERMEDIATE_STREAM".ROWTIME - TIMESTAMP '1970-01-01 00:00:00') minute / 1 TO MINUTE);
Pump は Amazon Kinesis Analytics リポジトリオブジェクトで、INSERT INTO stream SELECT ... FROM クエリ機能が連続して実行されます。FROM クエリ機能により、クエリの結果を名前付きストリームに継続的に入力できるようになります。このクエリは、HTTP リクエスト数を 1 分間のタンブリングウィンドウで計算するために用いられます。タンブリングウィンドウとは、固定サイズで、重複しない、時間間隔が連続している一連のウィンドウです。
ボタンがグレー表示になったときは、アプリケーションが「RUNNING」状態になるのを待ちます。その後、ボタンが利用できるようになります。。
| ROWTIME | STATUS | REQUESTCOUNT |
|---|---|---|
| 2018-02-11 06:25:00.0 | 200 | 94 |
| 2018-02-11 06:25:00.0 | 404 | 62 |
| 2018-02-11 06:25:00.0 | 301 | 2 |
| 2018-02-11 06:25:00.0 | 500 | 1 |
ウィンドウには多くの 404 リクエストが表示されています。その原因を突き止める作業を行います。
-- Create intermediate Stream for incoming data
CREATE STREAM "INTERMEDIATE_STREAM" (
hostname VARCHAR(1024),
logname VARCHAR(1024),
username VARCHAR(1024),
requesttime VARCHAR(1024),
request VARCHAR(1024),
status VARCHAR(32),
responsesize VARCHAR(32)
);
-- Data Pump: Take incoming data from SOURCE_SQL_STREAM_001 and insert into INTERMEDIATE_STREAM
CREATE OR REPLACE PUMP "INTERMEDIATE_STREAM_PUMP" AS
INSERT INTO "INTERMEDIATE_STREAM"
SELECT STREAM
l.r.COLUMN1,
l.r.COLUMN2,
l.r.COLUMN3,
l.r.COLUMN4,
l.r.COLUMN5,
l.r.COLUMN6,
l.r.COLUMN7
FROM (SELECT STREAM W3C_LOG_PARSE("browseraction", 'COMMON')
FROM "SOURCE_SQL_STREAM_001"
) AS l(r);
-- Define output stream that stores request counts by status
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (
status VARCHAR(32),
requestCount INTEGER);
-- Data Pump: Take INTERMEDIATE_STREAM and group into 1-minute intervals
CREATE OR REPLACE PUMP "OUTPUT_PUMP" AS
INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM status, COUNT(*) AS requestCount
FROM "INTERMEDIATE_STREAM"
GROUP BY status, FLOOR(("INTERMEDIATE_STREAM".ROWTIME - TIMESTAMP '1970-01-01 00:00:00') minute / 1 TO MINUTE);
-- Define an output stream that stores HTTP request and status
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM_404" (
status VARCHAR(32),
request VARCHAR(64));
-- Data Pump: Store status and requests in DESTINATION_SQL_STREAM_404 stream
CREATE OR REPLACE PUMP "OUTPUT_PUMP_404" AS
INSERT INTO "DESTINATION_SQL_STREAM_404"
SELECT STREAM status,request
FROM "INTERMEDIATE_STREAM"
WHERE "INTERMEDIATE_STREAM"."STATUS" = '404';
DESTINATION_SQL_STREAM_404 stream によって、アプリケーションサーバーからの、すべての 404 レスポンスがリアルタイムでモニタリングされます。
1、2 分後、DESTINATION_SQL_STREAM_404 stream に対して、以下のような出力が表示されます。
| ROWTIME | STATUS | REQUEST |
|---|---|---|
| 2018-02-11 06:27:51.952 | 404 | GET /img3.pn HTTP/1.1 |
| 2018-02-11 06:27:44.949 | 404 | GET /img3.pn HTTP/1.1 |
| 2018-02-11 06:27:52.961 | 404 | GET /img3.pn HTTP/1.1 |
新しい結果が、2~10 秒ごとに追加されます。上記の出力と類似した出力が表示されたら、ラボを続けます。これらの結果を得るため、DESTINATION_SQL_STREAM_404 stream が表示されていることを確認します。
このタスクでは、DESTINATION_SQL_STREAM_404 stream からの処理済みログファイルを Amazon Kinesis Firehose 使用して Amazon S3 に保存します。Amazon Kinesis Firehose ストリームを 1 つ作成し、このストリームを Amazon Kinesis Analytics アプリケーションの最終送信先として使用します。
タスク 2.1: Amazon Kinesis Firehose ストリームを作成する このサブタスクでは、Amazon Kinesis Firehose ストリームを作成します。
[20] ナビゲーションペインで [Data Firehose] をクリックします。
[21][Create delivery stream] をクリックします。
[22][Delivery stream name] にFirehose-log-streamと入力します。
[23][Source] に [Direct PUT or other sources] を選択します。
[24][Next] をクリックします。
レコードは、フォーマットの変更、タイムスタンプの挿入、必要ではない行のスキップなどのような AWS Lambda 関数で変換されます。直接レコードを変換できません。
[25][Record transformation] には [Disabled] を選択します。
[26][Next] をクリックします。
次に、Firehose 配信ストリームの送信先として Amazon S3 バケットを指定します。バケット名は一意である必要があり、例えば、kinesis-log-stream-123 のような乱数を追加することにより、バケット名をランダム化する必要があります。
[27][Destination] には、[Amazon S3] を選択します。
[28][S3 destination] セクションの [S3 bucket] で [Create new] をクリックします。
[29][Create S3 bucket] のダイアログボックスで、[バケット名] には、kinesis-log-stream-123 (123 の部分はランダムな数値に置き換えます) を入力します。
[30][Create S3 bucket] をクリックします。
[31][Next] をクリックします。
設定ページでは、配信ストリームのオプションを設定することができます。オプションには、(データサイズや間隔による) 記録が配信される頻度、圧縮率、ログ記録などが含まれます。Amazon S3 バケットへアクセスする Firehose によって使用される、新しい IAM ロールを作成します。
[32][S3 buffer conditions] のセクションでは、[Buffer interval] に60を入力します。
[33][IAM role] セクションで、[IAM role] に [Create new or choose] をクリックします。
[34][ロールの概要] が表示されます。残りの設定はデフォルトのままにして [許可] をクリックします。
[35][Next] をクリックします。
[36] ストリーミングの設定を確認し、[Create delivery stream] をクリックします。
ロールの作成には数秒かかります。ロールが引き受けられないというメッセージが表示された場合、数秒待ってから、再度 [Create delivery stream] をクリックします。
このサブタスクでは、作成した Firehose ストリームを、Amazon Kinesis Analytics アプリケーションに接続します。
[37] ナビゲーションペインで [Data Analytics] をクリックします。
[38][Analytics アプリケーション] ページで、[lab-log-analytics] をクリックします。
[39][アプリケーション詳細] をクリックします。
[40][[送信先に接続] をクリックします。
[41][送信先] には [Kinesis Firehose 配信ストリーム] を選択します。
[42][Kinesis Firehose 配信ストリーム] では、[Firehose-log-stream] を選択します。
[43][アプリケーション内ストリーム名] で [DESTINATION_SQL_STREAM_404] を選択します。
ポインタをそれぞれの名前の上にかざして、適切なストリームを選択します。それはリスト上の 2 番目のストリームです。
[44][出力形式] には [CSV] を選択します。
[45] 残りの設定はデフォルトのままにして [保存して続行] をクリックします。
[Save and continue] ボタンをクリックできない場合は、[Access permissions] を一時的に最初のオプション (Create) に変更し、その後 2 番目のオプション (選択) に戻します。これでボタンが有効になります。
これでお客様の Analytics ストリーム が、Firehose ストリーム を実装するようになりました。
このサブタスクでは、Amazon S3 内の出力ファイルを確認します。
[46][サービス] で [S3] をクリックします。
[47][kinesis-log-stream-xxx] バケットをクリックします。
対応ログファイルが、ラボの出力に対応していることを確認する必要があります。更新 アイコンをクリックして、コンテンツ一覧を表示します。データファイルをダウンロードし、テキストエディタで開きます。ファイルは、2 つのヘッダー、HTTP サーバーの要求、ログエントリのストリーミングから変換されたステータスを含みます。
お疲れ様でした。 このラボを完了しました。以下の手順に従って、ラボ環境をクリーンアップします。
[49] AWS マネジメントコンソールからサインアウトするには、コンソール上部のメニューバーで [awsstudent] をクリックし、[サインアウト] をクリックします。
[50] Qwiklabs画面で [ラボを終了] をクリックします。